If you are a recent university graduate, or you are not totally happy with your current job or career path, you may be seeking a way to gain experience, scale your abilities, and learn from mentors in order to build your career in a short period of time. The Wizeline Academy Data Engineering apprenticeship program offered us all of the above.
This program was composed of self-study material, mentorship, and sessions covering software engineering best practices. In this blog, we will discuss one of the projects we worked on during the software engineering best practices sessions. This specific project was presented in front of the entire company, so it was an amazing experience for all of us.
Our goal is to share our experience – including the good and bad parts of this project – as well as a bit about what we achieved.
Why?
In our software engineering best practices sessions, we started out by learning about good coding practices in Python and then continued on to pandas, DevOps, and more complex topics.
Once all topics in the main curriculum had been covered, participants were invited to suggest new subjects for future sessions. One of the most requested topics was data migrations; specifically, migrations to the different clouds. As we all know, there is no better way to learn than by getting your hands dirty. So, our mentor gave us total freedom to design the solution, architecture, and process to complete a database migration. We were divided into teams, and each team developed a different approach for the same set of data.
Our team consisted of three amazing women from different backgrounds: Andrea, a mathematician who is passionate about data; Laura, who has a bachelor’s degree in computer science; and Mariana, who has previous experience working as a data analyst.
We came up with the idea to migrate the transactional database to Cloud SQL and then use that data to build a data warehouse in BigQuery.
As is key for any data project, we did a lot of research into the best practices and considerations for data migration to the cloud. We faced many issues, but we learned a lot in the process.
Solution
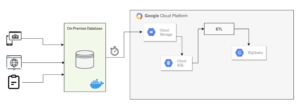
We started by brainstorming ideas for how to best approach the project. The initial architecture we built involved making a complete dump of the database every night using cron, then importing it to Cloud SQL. At this point, an ETL pipeline was executed in order to extract the data from Cloud SQL, perform a cleaning process, and load it into BigQuery. We migrated to BigQuery, using it as an analytical data warehouse. This allowed us to analyze any type of data at high speeds and obtain valuable insights. We found this solution to be effective for the amount of data provided.
Before the migration, we considered the requirements for verification of the destination data and the differences between Cloud SQL and standard MySQL.
Also, as part of the pre-data migration testing, we defined the source-to-destination mapping for each data segment. Doing so helped us develop the tools needed to meet cleanup requirements. This scope can be redefined over time, as pre-migration testing can reveal gaps and therefore adjust priorities.
For the migration, we considered schemas, data, authorization privileges, users, and pipelines. This first approach was an incremental migration, first with a bulk load and then with the migration of the pipelines from sources to Cloud SQL. To limit our scope of failure, we tried to segment our work into phases. This ensured the ability to recover from a failed phase via rollback to a prior phase state.
We also recognized the importance of data validation between the source and destination databases. We designed validation strategies to achieve:
- Completeness of data, by generating reports containing statistics that allowed us to see the similarities between the source and destination data sets.
- Data quality, by verifying that the fields and data types in the original data source and the target system matched, with their dependencies and interactions preserved.
For the current amount of data, the bulk migration accomplished our goals; however, it was not necessarily a scalable approach. So, we started researching Change Data Capture tools to help us capture changes made to the database in real time. We chose Debezium as our first option, mainly due to the documentation available and its integrated sink configuration.
The Debezium server is a configurable, ready-to-use application that streams change events from a source database to various messaging infrastructures.
Change events can be serialized to different formats like JSON or Apache Avro, after which they are sent to a messaging infrastructure such as Amazon Kinesis, Google Cloud Pub/Sub, or Apache Pulsar.
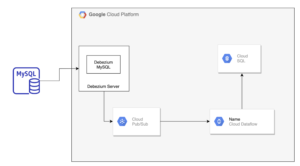
Pictured below is the resulting architecture for this stage. We used the Debezium server application to stream change events from the source database to Google Pub/Sub; then, we orchestrated the pipeline with Cloud Dataflow and synchronized with Cloud SQL.
The development of this full architecture is still a work in progress, but we feel it’s a solid approach thus far.
Conclusion
This was a challenging project that gave us the opportunity to put into practice the new technical and nontechnical skills we developed by participating in the apprenticeship program. We were somewhat lost on how to start the project at first, but we took this as an opportunity to gain knowledge and grow our skills.
We learned a lot by investigating and experimenting, and we also learned a lot from each other. Thanks to our mentor, we had the opportunity to present our project to a team of solution architects. After receiving positive feedback, we were invited to present it to the whole company in the team meetings for North America and APAC. This project allowed us to gain exposure to a real-life scenario, which was a very enriching experience.