
Introduction to Explainable AI (XAI)
With great power comes great responsibility. As AI grows in power through the advancement of technologies and methods, its practitioners must also take the responsibility to use it ethically and in a responsible way.
Consider an AI module that targets a particular population segment and offers them higher-interest loans. Unfair, unethical processes such as this one can result in brand and reputation damage, undermined client engagement, and even regulatory fines.
The purpose of explainable artificial intelligence (XAI) is to eradicate this kind of bias, among several other undesirable outcomes, and promote key features in AI models such as:
- Be understandable by themselves
- Be able to explain why and how they arrived at a decision
- The explanations are comprehensible by humans
The goal of XAI is to create AI modules in such a way that these needed explanations are part of the design process, leading to the responsible use of AI across industries. But there is a caveat: the simplicity vs. transparency trade-off. Simple, transparent models are not powerful enough, so data scientists rely on complex, opaque models. A linear model exposes the value of its coefficients so that it is obvious which variables contribute to the final prediction; in contrast, a neural network presents us with tens of thousands of values making it really hard to relate inputs and outputs. At the same time, the power of a neural network to find subtle relationships among variables is much greater than the linear model.
In this blog, we’ll discuss one of the key methods for making AI more explainable, explore the method in action, and talk about the potential business benefits of XAI.
Making AI More Explainable in Complex Models
Ingenious methods have been created to help in solving the tradeoff between simplicity and transparency, such as SHAP – SHapley Additive exPlanations (Lundberg & Lee, 2017). A Shapley value is the average marginal contribution of an instance of a feature among all possible coalitions. The contribution of an instance of a feature is calculated by looking at the model outcome with the presence of the feature and contrasting the model output without the presence of the feature. A paramount contribution of SHAP is how we can implement this notion with a large set of features through sampling.
SHAP is a kind of cooperative game, where a single prediction is a game and the features are the players. Each player gets a payoff by cooperating. A Shapley value is a distribution of the total gains. This method can work with any predictive model which takes a set of numeric features and produces a numeric outcome (that is, almost any narrow AI use case).
Let’s put this idea in action using 506 housing data points from Boston from the 1970 census. We will select four independent variables for the model, and the variable to be predicted is MEDV.
| Variable | Description |
| lstat | Proportion of adults without some high school education and male workers classified as laborers |
| rm | Average number of rooms per dwelling |
| dis | Weighted distances to five Boston employment centers |
| indus | Proportion of non-retail business acres per town |
| MEDV | Median value of owner-occupied homes in thousands of dollars (Target Variable) |
To run this experiment, we will use XGBoost to generate the model. XGBoost is a decision-tree-based ensemble ML method. Its core is the use of the gradient boosting framework. This is one of the best methods for small-to-medium structured/tabular data and represents an evolution from decision trees, bagging, and random forest.
A single decision tree generates a single prediction using all features; bagging creates several trees to perform a democratic voting process using all features; random forest creates multiple trees with a subset of the features; boosting uses outputs of other trees to inform the process, and gradient boosting errors minimizes errors. XGBoost incorporates all these features. This evolution increases classification power, but at the cost of increased opaqueness.
Enter XAI.
From the 506 records, 500 were used to train the XGBoost model and 6 were used for the test set. We ran the prediction of the model over these 6 records. Let’s consider two of these predictions:
| Test Record | lstat | rm | dis | indus | Prediction (MEDV) |
| 1 | 4.98 | 6.575 | 4.09 | 2.31 | 31.3 |
| 2 | 5.21 | 6.43 | 6.9622 | 2.18 | 24.85 |
For the first case, we get a prediction of $31,300. But how did the model get to this number? This is where SHAP can help.
We need to prepare data for explanation and specify the expected prediction without any features (i.e. the mean of the target variable), then we compute the Shapley values.
This is the output of the explanation. The graph on the left corresponds to the first case and the one on the right to the second.
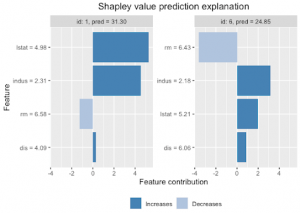
The image shows how lstat, indus and dis increased the prediction for the first observation, and rm decreased the prediction for the same observation. The magnitude of the value is also important to recognize. Notice that the effect of lstat is greater than indus. Now let’s analyze the second case: indus, lstat, and dis increased the prediction, but indus has the greatest effect. On the other hand, rm has a huge negative effect.
XAI’s Place in the Enterprise to Drive Responsible AI
By incorporating XAI, your company can keep using highly accurate, complex models while getting reliable explanations for their outputs. Here are some industry-specific examples that illustrate the benefits of XAI:
- For finance companies using classification models to help in credit scoring, XAI can provide an account of why credit is denied, help offer feedback to customers on how decisions were made, or even generate new, customized products based on customer data.
- As the healthcare industry seeks to deliver more personalized patient care using AI, a critical feature is the ability of models to provide explanations for their recommendations to patients due to the serious nature of these systems.
- Retail companies are using increasingly sophisticated customer segmentation models to drive their marketing campaigns, and an XAI component can be of great value to providing insight into why a customer is placed in a particular bucket.
No matter your industry, making sure AI is explainable is crucial to its long-term viability. At Wizeline, we understand the importance of enabling models to generate explanations to foster responsible AI while keeping business growing. To learn more about how Wizeline delivers customized, scalable data platforms and AI tools, download our guide to AI technologies and visit our landing page. Connect with us today at consulting@wizeline.com to start the conversation.
References
Lundberg & Lee (2017). A Unified Approach to Interpreting Model Predictions.





