
As our society gradually welcomes more AI capabilities in the form of image recognition and driverless cars, data science is becoming a hot commodity. Companies worldwide are collecting and storing massive amounts of data on consumption, users, and their behavior. This data comes in different formats and is rarely ever in perfect condition. Data scientists need access to high-quality data to work their magic. That’s where data engineering comes into play.
Data engineers build pipelines and frameworks that transform the data into patterns data scientists can work with. Because the role is farther removed from the end product, it may seem less glamorous, but it is just as valuable as (if not more than) the data scientist role.
“A good analogy is a race car builder vs a race car driver. The driver gets the excitement of speeding along a track, and thrill of victory in front of a crowd. But the builder gets the joy of tuning engines, experimenting with different exhaust setups, and creating a powerful, robust, machine. If you’re the type of person that likes building and tweaking systems, data engineering might be right for you.”
Data science encompasses everything from cleaning or normalizing data, to employing predictive models to gain insights. A data team can include data engineers, data analysts, and data scientists.
The core of data engineering
At the very core, a data engineer is a software engineer who specializes in working with tools to process, store, and move large amounts of data. Essentially, becoming a data engineer boils down to learning and mastering these tools, techniques, and algorithms. Some would argue that the role is closer to software engineering than data science.
Nevertheless, it is not a simple task. New technologies and techniques appear in the landscape at a rate that’s impossible for any human to keep up with. Beyond that, discerning which methods are worth studying can sometimes be difficult.
Although the data engineering field is broad, data engineers can specialize or focus on a set of skills within the field.
Data engineering requires skills in business intelligence and data warehousing, borrowing elements from software engineering. It can involve the operation of big data systems, as well as with concepts around the extended Hadoop ecosystem, stream processing, and in computation at scale.
At leaner organizations, data engineers might handle data infrastructure capabilities and responsibilities, which include ramping up and operating platforms such as Spark, Hadoop, Hive, and more. At a larger organization like Wizeline, data engineering is typically a formal role to manage the more robust data infrastructure needs.
Ramping up on data engineering capabilities
Because data engineering is somewhat of a new domain, companies are just starting to offer proper training for data engineering, and many universities still don’t offer courses in data engineering. Senior data engineers have to learn on their own or by working on projects that require this skill set.
Wizeline shares a vision and passion to educate more people about data engineering, data science, and how to approach the data lifecycle.
Our data team teaches a Wizeline Academy course in Spark, and we collaborate with prominent universities such as Tecnologico de Monterrey. We focus on learning and awareness, teaching best practices while advocating for our software engineers to ramp up in data engineering if they have the curiosity and the passion for it.
In addition, our data team creates internal guides to support new data engineers on their journey. Our goal is to train our people to keep pace with the slew of opportunities within data science.
Wizeline’s approach to the data lifecycle
What makes Wizeline special is that we have had the opportunity to work on those early data engineering projects that other companies have not. We have experience building enterprise-grade solutions. We are a multidisciplinary team that can see a solution and thinks about how to integrate the data solutions into the whole backend, how to build web apps with analytics, and how to integrate our data team to deliver a more complete or future-proof product or solution.
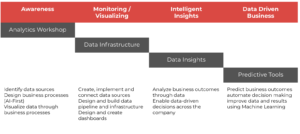
Step 1: Analytics workshop – We work to identify your data sources and design business processes, with careful consideration of your business needs, to achieve your organizational or product goals.
Step 2: Data infrastructure – Now that you know what to expect, it’s time to gather the data, sort, and refine it. This is a necessary step before the magic can happen.
Step 3: Data insights – This step usually doesn’t require complex modeling, but can paint a picture of what your future business can look like.
Step 4: Predictive tools – Some of the data science applications we discussed above come into play and we apply advanced modeling techniques. Here, the data begins to speak for itself, instead of someone having to really understand the intricacies of your business.
DataOps
Wizeline applies the principles of DevOps across our practices. We are working to define a data episode, taking the DevOps concept of being Agile and employing Continous Integration and Continuous Deployment to automate most of our development processes, but applying that to the data lifecycle instead. We are modularizing some of our advanced analytics and trying to build it as infrastructure as code. Our main goal is to take these models and build a data infrastructure in a matter of weeks or months, tying together the sources to better support our data scientists.




