
Large Language Models (LLM), like ChatGPT and Gemini, can be leveraged for a range of applications. At Wizeline, we’ve been experimenting with the latest technologies and trends, putting all of the popular LLMs to the test as we constantly build new solutions on top. Not only have we been honing our expertise in prompting styles and techniques for optimizing results for our custom AI-driven applications, but we’ve also been building a large body of research along the way.
This body of research provides some key insights into Multimodal Prompting, one of the hottest trends in generative AI right now. Multimodal Prompting is when multiple data types, formats, and files are used to create a prompt for Large Language Models. OpenAI has been doing this for some time already by integrating the Dall-E image generation model in ChatGPT 4, and Google is starting to get into the game, gradually incorporating Multimodal Prompting in Gemini.
How did this all start? Let’s take a closer look.
Act One: A Tutor to Inspire Experimentation
Most successful screenplays tell a story across three ‘acts,’ with Act One often used to set the scene and the plot.
Our first act begins with some simple questions. While we originally approached our work thinking about tools from a solely technical perspective, we recognized that most users of popular LLMs are not part of the technical realm. This realization led us to wonder, ‘what’s their experience like?
Outside of the tech space, LLMs are being used by swaths of people for content creation, writing and storytelling, and learning assistance, similar to how calculators are used for math! With that thought in mind, we set out on our research to explore how LLMs are meeting user needs. One of the suggestions involved treating LLMs as if they were Math tutors, using different prompting techniques, and starting with image-to-text generation. The rationale behind this approach is that current LLMs’ capabilities make them excellent assistants in various tasks, from coding to writing song lyrics. But for us, it goes beyond just creating content. Our goal is to learn throughout the process of interacting with these LLMs, and getting to know them on a deeper level that transcends technicalities and focuses on the traits that make LLMs more “human.”
The first experiment in this Math tutor series involved prompting both ChatGPT 4 and Gemini with an image including a graph of the basic sine function y=sin (x).
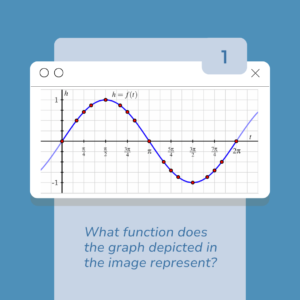
We attempted a zero-shot prompt with the question: “What function does the graph depicted in the image represent?” ChatGPT accurately identified the function and detailed its elements and values according to the image. In particular, the depicted function had a range between -1 and 1 and a period of 2π. When we entered the same image and question into Gemini, it mistakenly identified the function as y = 4 sin (3x), a function with a range of -4 to 4 and a period of 2π/3. Gemini additionally put forward a hyperlink including an image on which we assume it based this answer. The image included a graph of y = 4 sin (3x). This led us to believe that Gemini based its answer on this similar yet very different image to the one in our prompt. To us, in this first experiment, ChatGPT was the clear winner.
Using other techniques (such as few-shot and iterative-prompting) leveled the playing field between the two models. We asked them to behave like a very approachable professor and explain the graph in more simple terms, using analogies that could be easily understood by any audience. This approach provided better results from both models. Overall, from our perspective, we observed ChatGPT doing a better job of “impersonating” or assuming a specific human role when prompted. Meanwhile, Gemini, though not as human-like in its response, provided an answer that was better structured and more easily readable.
Act Two: The Potential To Resolve Conflict
The second experiment and our Act Two includes a more creative objective. It involved creating a character and developing a conflict/resolution story around it.
This experiment belonged to the image-to-text category and consisted of prompting both models with a cartoonish image of a man (downloaded from a Creative Commons image repository) and describing in the prompt who this man was and what he wanted to accomplish as part of its story.
This is a brief summary of the prompt, which encompassed a few-shot:

Image by Yorkun Cheng: https://iconscout.com/contributors/gee-me
ChatGPT was quick to search for data and list the possible natural catastrophes that could happen in the future. It also listed the best places for the Bunker, considering elevation (in case of floods), volcanic activity, and other variables.
On the other hand, Gemini simply responded with, “Sorry, I can’t help with images of people yet.” This was a surprise, as we had used a cartoon of a generic person that in no way resembled a real person, at least not one that in our opinion could be mistakenly identified using facial recognition technology.
This experiment proved that Google is more conservative in rolling out certain features of its Gemini model. In later prompts about this, Gemini replied with privacy concerns and its commitment to responsible AI use.
Act Three: Pushing Boundaries and Theories
Act Three and our third experiment focused on Text-to-image generation. Since at the time of the experiments Gemini was not yet able to generate images from text, one workaround to make a direct comparison was to ask both models to generate graphical representations of things using only ASCII characters. This yielded some interesting results, but definitely not what we were expecting.
To the zero-shot prompt:


ChatGPT 4’s response has a black background because it decided to format the response as a code block, as opposed to Gemini, which provided the response as plain text.
This experiment shows both models are weak performers for this specific application. There are better tools fitted for this purpose, but we felt it was important to test the creative limits of ChatGPT and Gemini.
Epilogue – Early Conclusions and Learnings
With technology and Multimodel Prompting advancing every day, we’ll likely be exploring a sequel to our experiments very soon. Still, it’s important to remember these comparisons, impressions, and observations represent early days, and should be taken with a grain of salt for a few reasons:
- The Only Constant is Change – We spent a considerable time gathering these early observations, and things change quickly in the world of GenAI. We’re confident that many things have changed from the time of these experiments to the time of this publication.
- Additional Rigor is Needed – Our methodology for these experiments did not follow a strict methodology or rigorous approach regarding metrics and qualitative analysis. Our main focus and objective was to find subtle differences in the way different models behave when prompted with similar data in prompts.
- Fail Fast and Deliver Better, More Informed Solutions – We could certainly identify certain biases and ways of “reasoning,” but ultimately, these kinds of experiments enable us to pinpoint the strengths and weaknesses of each model so we can deliver better ideas and solutions to our clients.
At Wizeline, we are committed to experimenting with existing and new GenAI models to test the limits of what’s possible and what to expect, all while sharing our reviews, insights, and impressions.




