I’ve been working on mass media projects for almost two years now. Two of my favorite projects were building publishing platforms. Both leveraged the headless CMS architecture and developed a platform around it.
While the stacks were entirely different, the patterns between architectural components seemed the same.
I started to identify the same patterns in older systems I had worked with before, and I wanted to know if I could apply the same patterns to a legacy system.
A friend was building new versions of the Android and iOS apps for an old CakePHP app in the healthcare industry that I helped develop almost five years ago. He wanted to add new features to the apps and needed the backend to support the new features.
The CakePHP app interacted with data coming from an external system. It was the source of truth for most of the entities in the app. Both systems were tightly coupled, sharing data via database tables.
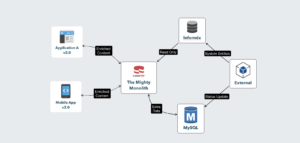
Data for things like product names, system IDs, pricing, product status, user accounts, membership status, and stock levels come from the external system.
Doctors and practitioners would log in to the CakePHP app and add more information to the data coming from the external system.
Models for product descriptions, pictures, calendars, procedures, locations, and profiles only existed in the app, and that data was created and managed there. The app would render the content and expose the data via a REST API to mobile and third-party apps. One big, mighty monolith from the good ole’ days.
I convinced my friend to let me start building experiments around the project. I began strangling the monolith. After several iterations, this is the resulting architecture:
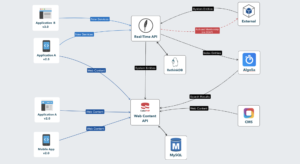
The Platform
The new platform is an event-driven, distributed system. A FeathersJS RESTful layer in the middle of the platform. I offloaded all content related responsibilities to Prismic.io, the CMS functionality on CakePHP was deprecated. I used Algolia to power the search engine on all apps, including the API.
Based on the events of the API, I can do things like index new content or remove content from the search engine, update pricing, stock levels, enable or disable content, and bake in some default data in case an entity does not exist on the CMS yet.
As a nice bonus, the mobile apps can now give notifications to users real-time about things that are happening in other parts of the platform.
No shared databases
I started by removing the database dependency between systems. Now all systems integrate via RESTful API endpoints.
The coupled integration was the source of a lot of pain points:
- Schema changes from external updates: Whenever the external system’s schema was updated, the backend needed to be updated too. Some of those changes could tickle all the way up to the mobile apps.
- Cascaded down-time: Because the external system was the source of truth for things like membership status and identity, it would cause partial failures on other systems when it went down for any reason. Local cache helps but only to some extent.
- Batch syncs: Because the systems integrated via the database some things needed synchronization with daily jobs. Things like price lists, stock levels, and search indexing on Lucene; all had to run at the end or beginning of each day.
- Ownership: Because there was very little visibility, there was a lot of tension between those who maintain the external system and the backend engineers when something went wrong.
Now the external system pushes changes via the REST API. They exposed a SOAP API for user membership which the Feathers’ backend consumes and proxies as JSON API for external clients.
The Headless CMS
I modeled all content entities in Prismic. Users can now create and manage content and see it magically appear on all apps in near real-time.
I kept Cake’s front-end as is. Keeping it as the rendering engine means that no extra effort is needed in the front-end. In the future, the company wants to migrate to VueJS or React.
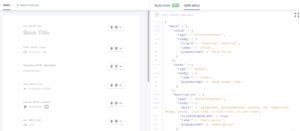
I set up webhooks to sync that data back to CakePHP models. The content coming from Prismic will update existing models, handle external assets (backing them up locally) and update current state. Eventually, all content will exist in Prismic.
From previous experience, I knew that data migration is always a lot of work. Thankfully, no data migration was needed in this case.

The Search Engine
Working with Algolia is a breeze. It’s blazing fast and easy to use. Having an event-driven architecture turned out to be extremely beneficial. Events on the API use NodeJS’ client to index the data asynchronously.
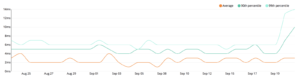
In a few milliseconds, the search features on all applications will reflect the changes and show (or hide) the same results. SDKs for PHP, Swift, and Java made the integration easy.
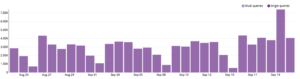
For any existing clients that were not updated, the CakePHP search continued to work as it did before (powered by Algolia behind the scenes). This also meant that other integrations like Chrome’s Omnibox search continued to work.
Continuous Deployment
Having more pieces in the architecture meant that deploying new versions of the platform can no longer be done by hand. I set up pipelines on Buddy to handle the deployments automatically.
The CakePHP app was already being deployed to an EC2 instance on AWS. I just had to automate the process (and added atomic deployments).
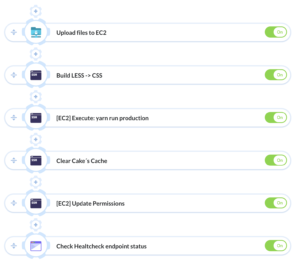
The FeathersJS app is deployed to the cloud with Zeit’s Now, a service for immutable infrastructure that makes it simple to deploy features quickly without hassle (or fear).
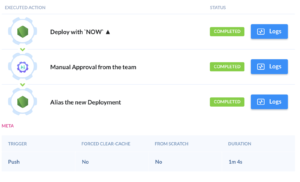
Merging a branch will create a new container tied to a new domain name where you can do any tests you need.
If everything works as expected, the last step will alias the current deploy to the backend’s public DNS name and it will automatically start receiving live traffic. It will also automatically scale the app and make sure it’s running in all available regions.
The configuration for aliasing to production and scaling rules are set in the repository as code. The database connection and the access keys for third-party services are set as environment variables that are injected to Now from the pipeline.
MySQL database lives on Amazon’s RDS. The RethinkDB database is hosted in compose.io, using a three node cluster configuration plus a proxy portal node (and automated backups).
Debugging and Tracing
Breaking the monolith apart made the overall architecture easy to understand, easier to maintain, and evolve. But at the same time made debugging very hard. Trying to figure out what’s going on when an event crosses system boundaries was very challenging.
I had already some idea about observability and traceability because of my experience with AWS Lambda, X-Ray, and IOPipe. I really like IOPipe, but it only works for Lambda. I remembered reading great insights on observability via Charity Majors’ twitter. I decided to try Honeycomb.io.
I instrumented the backend and the pipeline.
Feathers uses ExpressJS under the hood, so I just had to add their beeline for NodeJS and HTTP requests were handled out of the box.

NodeJS Honeycomb Beeline
I used before and after hooks to add extra context to the tracing information. That helped get better insight into what was going on in the platform and made it easier to build meaningful queries and create visualizations with values that made sense business-wise.
There is no beeline for PHP yet. But the Events API can be used with all other languages.
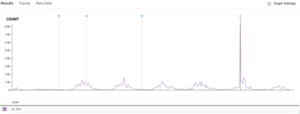
I also instrumented the pipeline so all releases are marked on Honeycomb (the blue combs on the image above). I used the marker CLI for that. With pipelines already setup to run when code is merged to master and tagged for release, it was just running one extra step with the following:
$ honeymarker -k $HONEYCOMB_KEY-d feathers-ws \ -t release \ -m "$EXECUTION_TAG" \ add
Triggers can be leveraged to keep track of any unexpected behavior across the platform. I expect that in the future Triggers will be used to track behavior after an update performing roll-backs or aliasing the release automatically.
I learned a lot! The platform is robust, decoupled, and scalable. It helped me validate my theory around content platforms and helped recognize reusable patterns I can easily apply in different projects.
On the other hand, it made me realize that replacing a monolith with a distributed system helps in the long run but adds a lot of complexity that can be cumbersome if you don’t have the right tools support it like CI/CD, event logs and tracing.
I think observability is a key success factor when building service-oriented architectures like microservices or Lambda-based architectures. I’ll continue to dig more into it.
Finally, the team that will continue to support the platform was also delighted with the outcome. It’s now easier to add new features. Understanding the components is straightforward, more than the original codebase was. They are already thinking about what the next refactor will be — the front-end. The organization has less aversion to change, and new ideas are already in the pipeline. They are moving faster, and there’s a new sense of trust in the engineering team.