Recently, part of our Colombia team hosted our inaugural in-person AI Meetup at Wizeline’s Bogota office. Attendees dove into cutting-edge AI technology and data engineering, discovering the powerful interplay between ChatGPT‘s API and Spark for advanced analysis of CloudWatch Logs.
The event was a collaboration between Wizeline and the Apache Spark Bogota community, led by Miguel Diaz (Global Machine Learning Engineering Director at AB InBev). Over 70 people attended, eager to learn from Wizeline’s experts and network with industry professionals working with generative AI tools.

Event Highlights
- Spark and ChatGPT integration: Our expert data engineers, John Sanchez, Juan Pulido, and Milton Sanabria, showcased the advantages of merging Spark’s data processing capabilities with ChatGPT’s natural language generation. They demonstrated how this integration can efficiently analyze CloudWatch Logs, identify errors, and provide actionable insights for optimal service execution using the right parameters.
- Uncovering hidden patterns: Through practical examples and real-world use cases, our engineers revealed how integrating EMR Serverless with OpenAI API can reveal hidden patterns in expansive CloudWatch Logs. Attendees saw firsthand how AI-driven analysis can expedite data transformation and semantical workflow analysis, enhance troubleshooting, and drive overall operational efficiency.
- Enriching data with OpenAI API: Our team highlighted how the OpenAI API can augment CloudWatch Logs. Attendees learned how AI-generated content can enhance data quality, uncover correlations, and fuel data-driven decision-making.
- Networking and collaboration: The meetup offered attendees, including software engineers, a unique opportunity to engage with industry peers, exchange views, and discuss innovative trends in AI-powered data engineering.
Context for the Problem and Solution
ChatGPT: Unleashing the Power of Conversational AI
ChatGPT, an AI product by OpenAI, soared in popularity because of its humanlike interactions and adept chatbot capabilities. It quickly generates fluent and coherent responses, even in complex discussions.
Rooted in generative AI, ChatGPT harnesses machine learning techniques, such as neural networks, to learn from vast datasets and create diverse digital content. Its core architecture, the “Transformer,” revolutionizes natural language processing and improves responses through reinforcement learning.
Despite its great potential, artificial intelligence tools like ChatGPT do have limitations, such as producing biased or vague responses in some cases. Still, Its potential to enhance automated conversation remains immense.
Data Engineering Empowered by AI: Revolutionizing Data Processing
Many companies struggle to extract meaningful insights without efficient data engineering because of disorganized data and suboptimal infrastructure. AI streamlines this process by automating tasks like data profiling and cleansing, thus improving data quality and reducing manual effort.
Based on the above, our engineers highlighted AI’s transformative role in data engineering. They started the roadmap to simplify enrichment processes by transforming a dataset (CSV file) with the OpenAI API, taking advantage of the following AI capabilities:
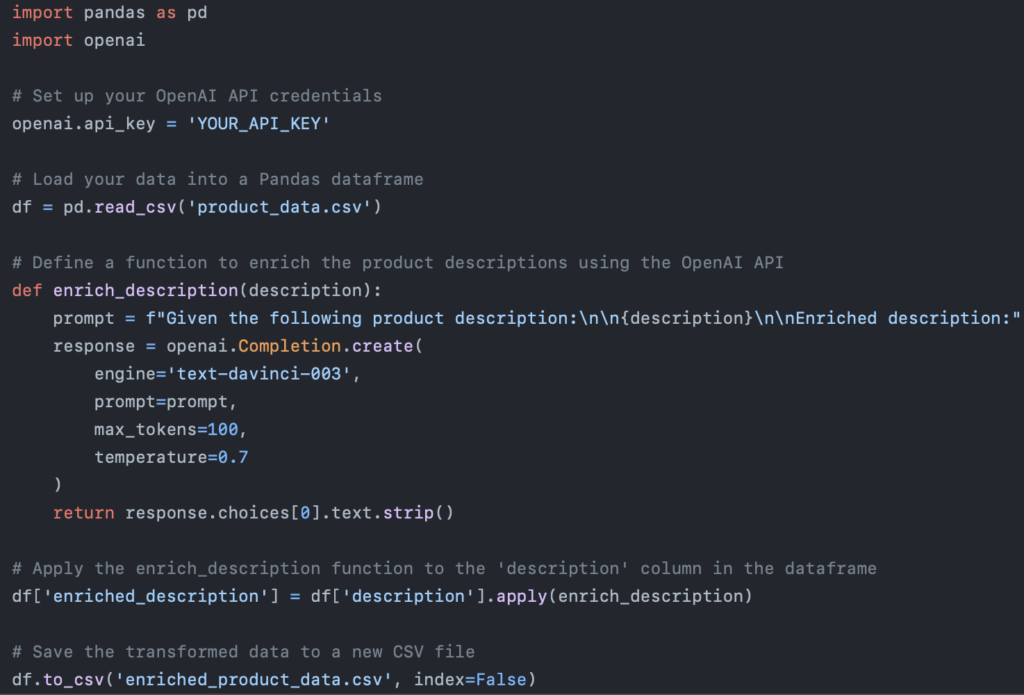
*Data enrichment powered by AI*
This code snippet demonstrates a richer use case for a company’s products.. Instead of returning the input as plain text, we format it in a tabular data format, a functionality data engineers find more compatible with libraries like pandas, PySpark, polars, and more. Data privacy concerns also influence how we handle and transform this data.
A critical question arises: Will this approach become mainstream moving forward? The industry is still researching concepts like AI-driven data cleansing and data augmentation. Software engineers, among other professionals, realize that a significant amount of work remains before we can fully leverage AI for these processes.
These tasks, particularly with big data, can be extremely time-consuming. Therefore, methods to improve prediction speed and the potential for parallel inference are promising areas that require further investigation.
Spark Job with EMR Serverless: Scalable and Efficient Data Processing
During the proof-of-concept (POC) phase, we ran the Spark job using traditional EMR workspaces with a cluster, providing us greater control over the settings and applications. Our objective was to validate this code snippet’s functionality before moving to EMR Serverless, but we faced unexpected issues.
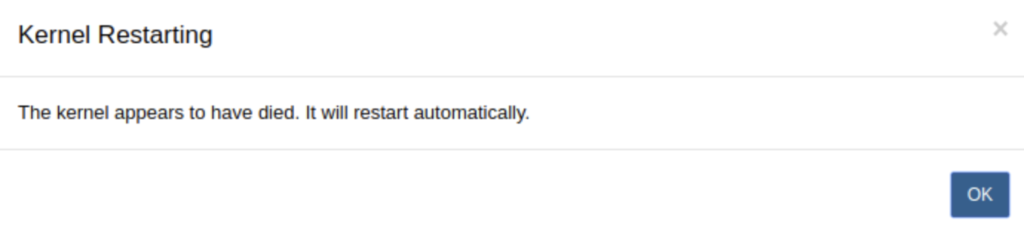
*Kernel shortages resulted from insufficient resources to run the Spark job*
To address challenges, we optimized EC2 machine performance in the EMR cluster and adjusted the EMR Roles permissions. This ensured our Spark job ran successfully. Our focus remained on migrating the job to a serverless environment. Each challenge we encountered taught us valuable lessons that propelled us forward
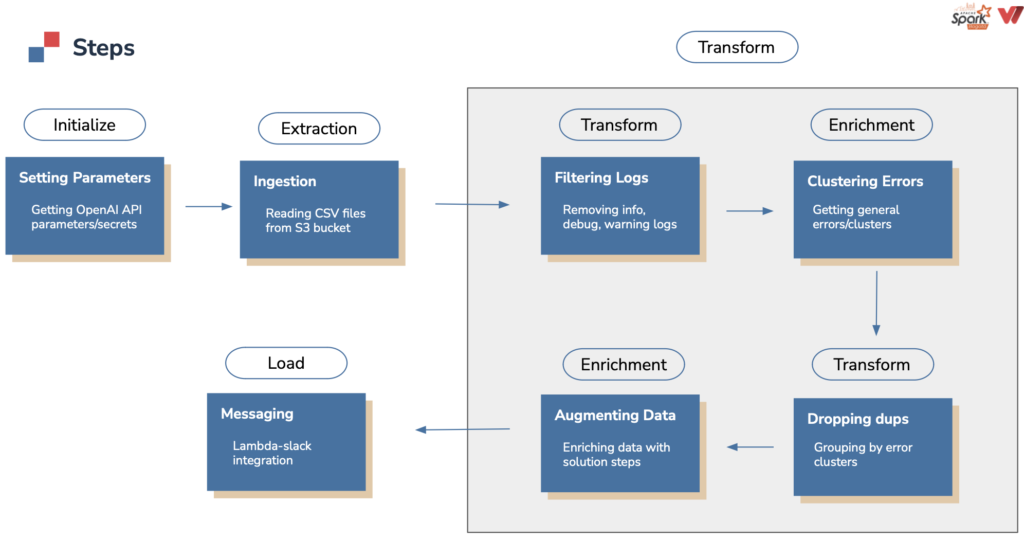
*Spark job internal logic, step by step*
Setting up a serverless EMR application in AWS with an AI-powered Spark job was an intriguing challenge. We intended to harness Spark’s processing power in a flexible, cost-effective serverless architecture. However, we encountered complications when deploying on private subnets. We addressed this by adjusting our VPC configuration using a bastion host or NAT gateway, ensuring a reliable connection to the OpenAI API.
 *EMR Serverless only works over private subnets*
*EMR Serverless only works over private subnets*
After creating the application, high demand on the OpenAI API sometimes led to timeouts, posing a risk to our infrastructure. Our application’s consistent performance relied heavily on the API’s availability and seamless functioning.

*Timeout error when OpenAI API is busy*
Upon stabilizing the Spark job, we stored compressed Python libraries in an S3 bucket and sensitive information in AWS Secrets Manager, simplifying code adjustments. Furthermore, integrating a Lambda function allowed us to publish log analysis results directly to a Slack channel, highlighting AI’s role in data engineering and analytics.
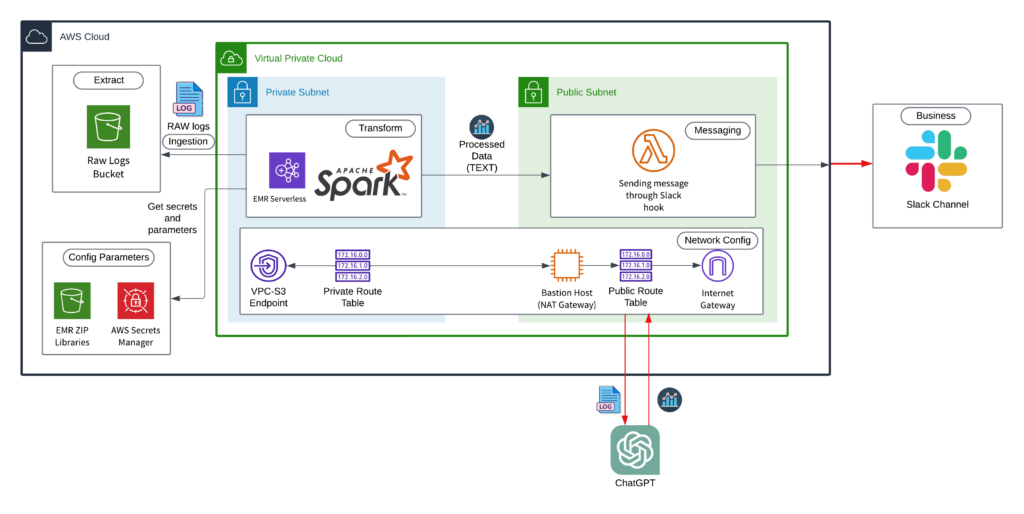 *Architecture diagram*
*Architecture diagram*
By addressing challenges and refining our EMR Serverless app, we realized the immense potential of AI-driven technologies. Our journey involved adapting our infrastructure, addressing timeouts, streamlining code, and integrating with Slack, resulting in a remarkable demonstration that deeply resonated with our team and audience.
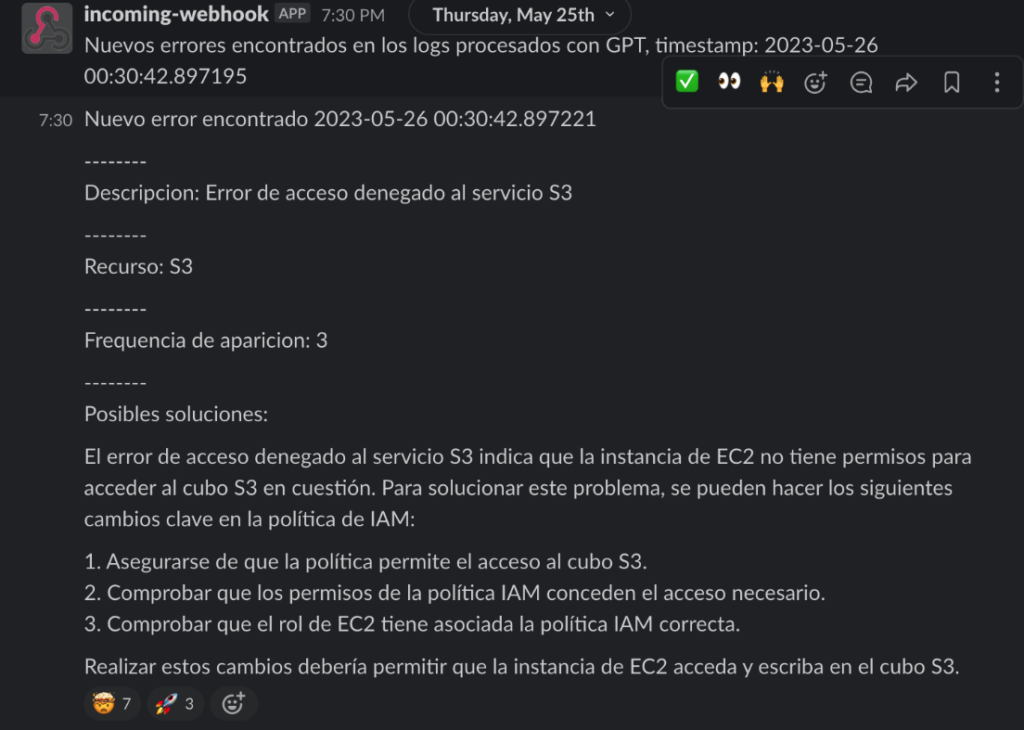 *Results sent via Slack*
*Results sent via Slack*
Key Takeaways from the Exercise
AI in data engineering: AI speeds up data cleaning and transformation, but large language models (LLMs) like using ChatGPT can introduce delays with big data due to processing time and protocol limitations. Ensuring fallback for APIs like OpenAI is critical due to potential failures. Exploring open-source LLMs like LLaMa, Alpaca, or Vicuna may be beneficial but requires a comprehensive feasibility analysis.
Prompt engineering skills: Prompt engineering skills are increasingly critical for data engineers. Providing clear instructions ensures obtaining relevant responses from language models. Addressing concerns about information security, data privacy, and AI understanding is crucial.
Measured adoption of AI in data engineering: While AI brings excellent benefits to data processing, existing challenges must be addressed. Equipping yourself with specialized skills and knowledge is essential to leveraging AI’s full potential. Acknowledging benefits, addressing issues, and focusing on skill development can optimize processes and drive impactful results.





