
Building a Knowledge Graph to Help a Global Media Company Deliver Timely Information to Users
Executive Summary
Our client, a global media firm headquartered in New York, has invested heavily in intelligently structuring data and news while connecting it to customers’ needs. Part of this investment is a new company department that aims to remove the friction in knowledge access and make personalization at scale possible.
Wizeline collaborated with the client to bring this department to life, leveraging machine learning and artificial intelligence technologies to ultimately build a knowledge graph that improves users’ access to timely and relevant information.
Leveraging an Extensive Database to Provide Critical and Timely Information for Customers
Our customer sits on a trove of proprietary data stored in varying structures. The amount of facts and articles derived from over 50 years of digitized media is massive, making it challenging to navigate to provide actionable and data-driven decisions.
Customers are bombarded with information and struggle to identify what news affects their interests. Unable to decipher what is signal and what is just noise, they can’t take timely, decisive action. One thing is clear — more information is not the solution. Our client’s customers need critical information at their fingertips without having to sift through a pile of newsletters.
Given the trustworthiness that this new department aims to gain, signals need to be as actionable and accurate as possible. Customers wouldn’t tolerate yet another newsletter with a high percentage of noise. B2B sales executives are one of the leading prospects for this solution. They leverage the readiness and accuracy of the information available to make better decisions, i.e., if several signals indicate an impending opening of a new facility, this may prompt new business opportunities in a whole ecosystem of providers.
These customers could have very different requirements, such as news focused on specific geographic regions, size of investments, industries, job ranks, and numerous other fields that bring true value to their businesses.
Automating reading the news requires a technical solution that can build a layered context around a concept by detecting entities linking them to a single source of truth. Critically, it had to incorporate data from both structured and unstructured data sources. Furthermore, our client needed a solution that was scalable, updates quickly, and operates well at high volumes — after all, the news changes minute to minute.
Building a Knowledge Graph Understandable by Humans and Readable by Machines
The new department ultimately settled on a knowledge graph as the solution, requiring Wizeline to create a complete view of the news that is understandable by humans and readable by machines. The graph is the semantic glue for all the varying criteria and a key enabler of knowledge inference.
Transforming the news to comply with our ontology, delivering customer-ready signals, and powering other products required several data pipelines and processes. Here is a brief explanation of the main pipeline developed for the first release, orchestrated with Cloud Composer Apache Airflow processing millions of articles:
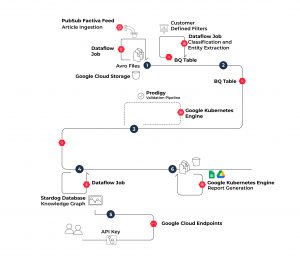
- A continuous feed of signals is ingested into a bucket-based data lake. Here, raw data is stored for traceback and historical records. Different filters and heuristics are applied for the project’s varying customers.
- The feed of signals is processed using a pluggable internal classification tool to define the type of signal it contains and extract more information about it.
- An optional validation process can be used for signal validation, annotation, and correction to ensure the quality of signals.
- Corrected entities are stored in the knowledge graph and can be accessed by clients through the project’s APIs.
- The project’s APIs allow customers to query information on demand. Additional endpoints enable customers to grant permissions and create resources to support B2B application integrations.
- This feed is delivered in CSV, xslx, and spreadsheet format based on customer business logic. Reporting files are also stored in a Google Cloud Storage (GCS) bucket for backup.
Launching Version 1.0.0 to Deliver Signals to Paying Customers
After months on this project, we released the 1.0.0 version to start delivering signals to our client’s first paying customer. Also, in addition to the main pipeline, Wizeline contributed directly to lay the foundation for the rest of the products to be powered by the project across the company by:
- Developing a front-end components library to consume Resource Description Frameworks (RDFs)
- Managing all GCP resources with Infrastructure as Code (IaC)
- Automating the release flow
- Shifting left security with Berglas and Hashicorp Vault
- Creating a proprietary human-in-the-loop platform for third-party validators
- Testing a data portal based in the Comprehensive Knowledge Archive Network (CKAN) with customizations
- Setting the infrastructure to efficiently ingest tons of legal court cases from third-party providers
Furthermore, the project exposed the Wizeline team to lots of innovative technologies, resulting in many team members getting certified as GCP Data Engineers.
What’s Next?
In the future, Wizeline will continue leading knowledge graph development for the client with the following goals:
- Developing and testing new extraction and classification machine learning approaches with the thousands of validated records we’ve attained
- Publishing some of the APIs into the client’s developer portal
- Onboarding new paying customers for the client
Wizeline has extensive experience in Google Cloud Data Engineering with multiple successful projects, including knowledge graph development, AI and machine learning, and advanced analytics. If you’d like to learn more about how Wizeline can help you bring your next Data Engineering project to life, visit our solutions page here or contact us at consulting@wizeline.com.
Other Case Studies

How Wizeline’s AI Academy Catalyzed Generative AI Innovation in Mexico’s First Hackathon
Read more >>

Helping a Major Media Enterprise Increase Article Visibility with a New Web Rendering Platform
Read more >>


Leveraging MLOps to Deliver Improved Predictive Analytics for a Supply Chain Analytics Company
Read more >>
Helping Etsy Migrate Its Data Warehouse From On-Premises to Google Cloud Platform With No Downtime
Read more >>
