
Performing a Data Warehouse Migration to Cut Cloud Computing Costs by 50% for a Leading Media Company
Executive Summary
In 2020, Wizeline helped a leading US media and journalism company migrate its existing data warehouse from Amazon Web Services (AWS) Redshift to Google Cloud Platform (GCP) BigQuery to reduce the processing time for critical processes like report generation and save more on cloud computing fees.
Read more to see how the Wizeline team approached the problem and implemented a new GCP-based data architecture, reducing the time it takes the client to generate reports on key news metrics across 15 different business units from 11 hours to just 5 minutes while cutting cloud computing costs by 50%.
The Challenge: Assessing the Redshift-based Data Architecture
The client needed to migrate its existing data warehouse from Redshift (Jenkins, Redshift, Mesosphere DC/OS, S3, EFS) to BigQuery (Cloud Composer a.k.a. Airflow in K8, BigQuery, GCS, DataStudio) to help generate key reports faster and accelerate its business.
Prior to the migration, the customer had all its infrastructure running in EC2 instances managed by DC/OS, and all the services, including Jenkins, Grafana, and Cassandra, were running inside a Docker Container. Jenkins was used as an Orchestrator tool, and every job was contained in a Docker image.
Redshift was the primary destination for all the pipelines, but for some exceptional cases, an XLS file was created daily with extracted data from BigQuery, which the client was using as a secondary data warehouse before partnering with Wizeline.
To generate these files, Wizeline needed to extract the data from BigQuery to Google Cloud Storage (GCS), transfer those files to S3, and then load them into Redshift. The challenging part was that the data in BigQuery was stored as Nested Fields — something that Redshift does not support. This created the need to flatten the tables before extracting them to GCS.
The generation of these reports was managed by a dedicated script running on Jenkins and included 13 months of data calculated daily for 15 different business units. One of the tables had close to 50 billion records, and the whole reporting process took around 11 hours to finish.
This process was the cornerstone of the project because the reports provided insights into customer segmentation and preferences, enabling the business to see which news had more engagement. Based on these reports, the team established a budget and provided information to the C-level executives.
Another challenge was that some jobs had to handle large compressed files. The average size of these files was 3GB, and once uncompressed, they were around 500GB. These files had to be enriched (some columns were introduced, e.g. revenue or specific metrics due to the business needs), re-encoded, and converted from CSV to JSON.
The existing solution needed a 2TB Elastic File System attached to store the original and processed data (compressed and uncompressed) and then process one file at a time using 1.5TB of the EFS and clean it up before processing the following file. (In future references, we will call these the MG2 files.)
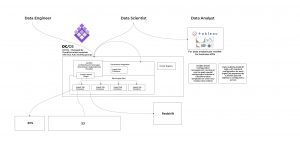
The client’s initial AWS S3/Redshift data architecture
Transforming the System to Improve Report Generation From End to End
The Wizeline project team of 3 Data Engineers and 1 SRE Engineer migrated all the files into GCP, and Google Composer (Airflow on Kubernetes) was used as the main orchestrator. We had to translate every pipeline into an Airflow DAG, and all the data was stored in Google Cloud Storage in RAW and processed format and then loaded to its final destination, BigQuery.
For the DAG implementation, we took advantage of the distributed system offered by Composer using multiple Kubernetes Pods and implemented workers inside each DAG that were created to handle high demand. In other words, inside a VM instance, we had numerous K8 Pods, and inside each Pod, we had multiple tasks, and inside each task, we had various threads taking care of the workload.
For the MG2 files, we implemented a streaming process. Instead of downloading, uncompressing, transforming, and then uploading the file again, we downloaded the file to store it compressed in memory (the max file size seen was 4GB). On the fly, we uncompressed the file by chunks, and those were processed as needed (re-encoding from iso-8859-1 a.k.a Latin-1 to utf-8, adding more columns and converting them into JSON) and then stored in an already compressed file in memory.
In the end, we had in the worst-case scenario 8GB of RAM used (4GB from the Original and 4GB from the Processed file). This removed the need for big disk storage, and since everything was stored in memory and no data was written in the disk, the process was cheap and pretty fast. We accomplished this using the GZIP Python library and the streaming tools already provided by Python.
We also migrated some Tableau dashboards to DataStudio and Looker. The Analysts were able to run the queries directly from BigQuery, allowing us to establish a monthly quota for each Analyst and keep track of the budget.
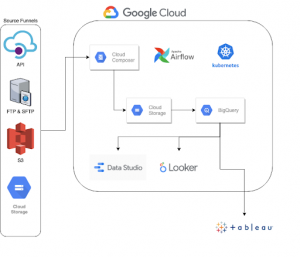
The client’s current GCP-based GCS/BigQuery architecture
The Result: Saving 50% on Cloud Fees & Reducing Report Generation Time From 11 Hours to 5 Minutes
In roughly nine months, we accomplished the data migration from S3 to GCS and Redshift to BigQuery, as well as translated all pipelines from Python to Airflow DAG. Many optimizations were made in the process:
- Instead of having a couple of tables with a lot of data for the reports, we created a table with the aggregated daily information for each business unit.
- Now that the DAG is able to handle report generation, the client can execute all 15 business units’ reports simultaneously.
- The whole process went from 11 hours to just 5 minutes, saving time and money because there is no need to flatten the tables, extract the data, or transfer it anywhere
Thanks to the completed data warehouse migration and these enhancements, our client now saves around 50% on cloud computing fees and enjoys an optimized system, allowing their teams to generate critical business metrics faster while accelerating growth.
Other Case Studies

How Wizeline’s AI Academy Catalyzed Generative AI Innovation in Mexico’s First Hackathon
Read more >>

Helping a Major Media Enterprise Increase Article Visibility with a New Web Rendering Platform
Read more >>


Leveraging MLOps to Deliver Improved Predictive Analytics for a Supply Chain Analytics Company
Read more >>
Helping Etsy Migrate Its Data Warehouse From On-Premises to Google Cloud Platform With No Downtime
Read more >>
